






Wanneer LookML de inkomsten centraal definieert, haalt elk dashboard, Explore en gepland rapport hetzelfde cijfer op, op dezelfde manier berekend. De afstemmingsvergaderingen verdwijnen omdat er niets meer is om af te stemmen.
Met de Explore-functionaliteit van Looker kan iedereen met toegang uw gegevens snijden en filteren op basis van het LookML-model, zonder dat dit nodig is. De vangrails zijn ingebouwd in het model, zodat selfservice accuraat blijft.
Een goed gestructureerd LookML-model is gebouwd om uit te breiden. Nieuwe dimensies, nieuwe metingen en nieuwe Verkenningen komen bovenop wat er al is. U herschrijft de basis niet telkens wanneer u een productlijn toevoegt of een nieuwe markt betreedt.
Looker verplaatst de berekeningen naar uw datawarehouse. Dankzij geaggregeerd bewustzijn, PDT’s en cachingstrategieën die in het LookML-model zijn ingebouwd, blijven de queryprestaties behouden als het aantal rijen toeneemt.
Rolgebaseerde toegang betekent dat directeuren het volledige plaatje zien, projectleiders hun eigen portfolio zien en financiën zien wat ze nodig hebben. Het juiste detailniveau bereikt de juiste persoon zonder dat iemand ziet wat hij niet zou moeten zien.
Looker is warehouse-native: BigQuery, Snowflake, Databricks, Redshift. We zorgen ervoor dat de verbinding tussen uw magazijn en uw LookML-model schoon is en dat de querypatronen die we bouwen, gebruikmaken van hoe uw magazijn is geoptimaliseerd.
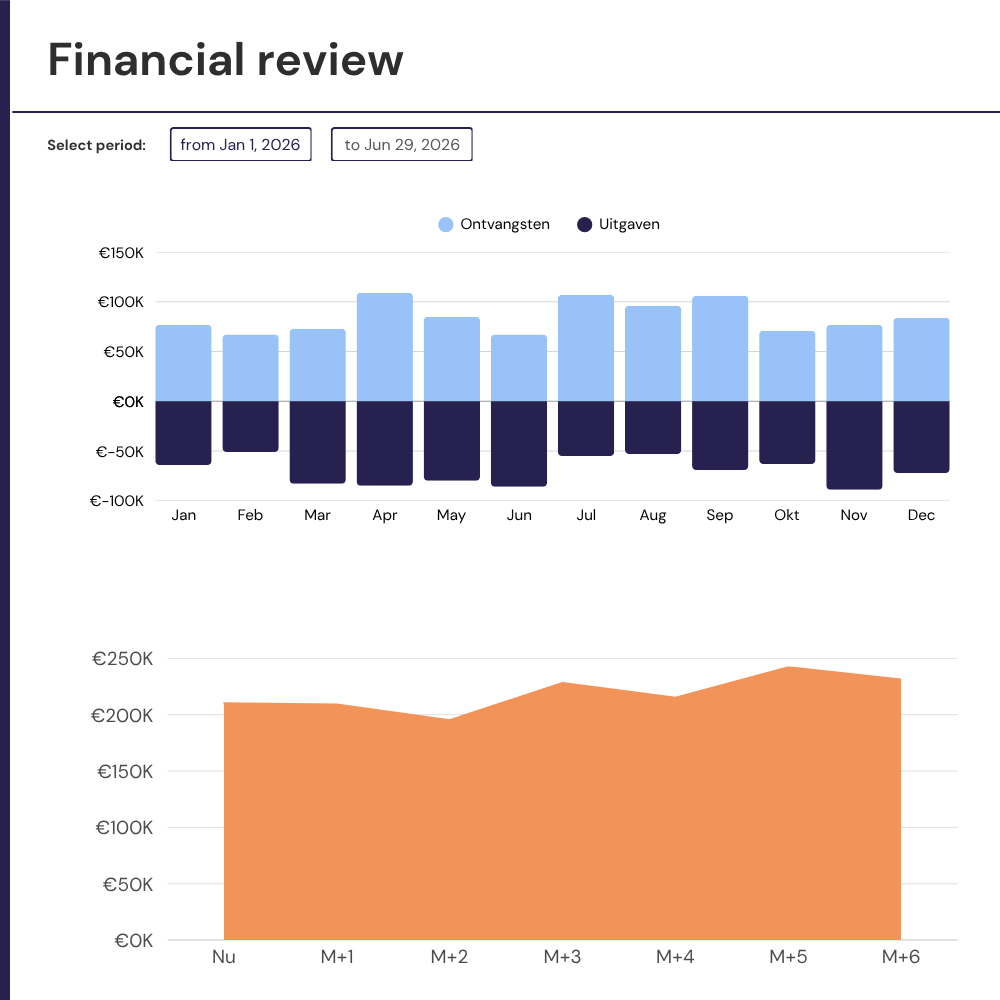
Aangepaste Power BI-dashboards bovenop uw bestaande gegevensbronnen, verbonden met uw live systemen, ontworpen rond uw bedrijfslogica en gebouwd zodat u ze kunt openen en onmiddellijk kunt vertrouwen op wat u ziet.
Looker implementatie vanaf de basis: LookML-datamodel, aangepaste dashboards en toegangsbeheer voor bedrijven die een beheerde analyselaag nodig hebben waarop ze echt kunnen vertrouwen.
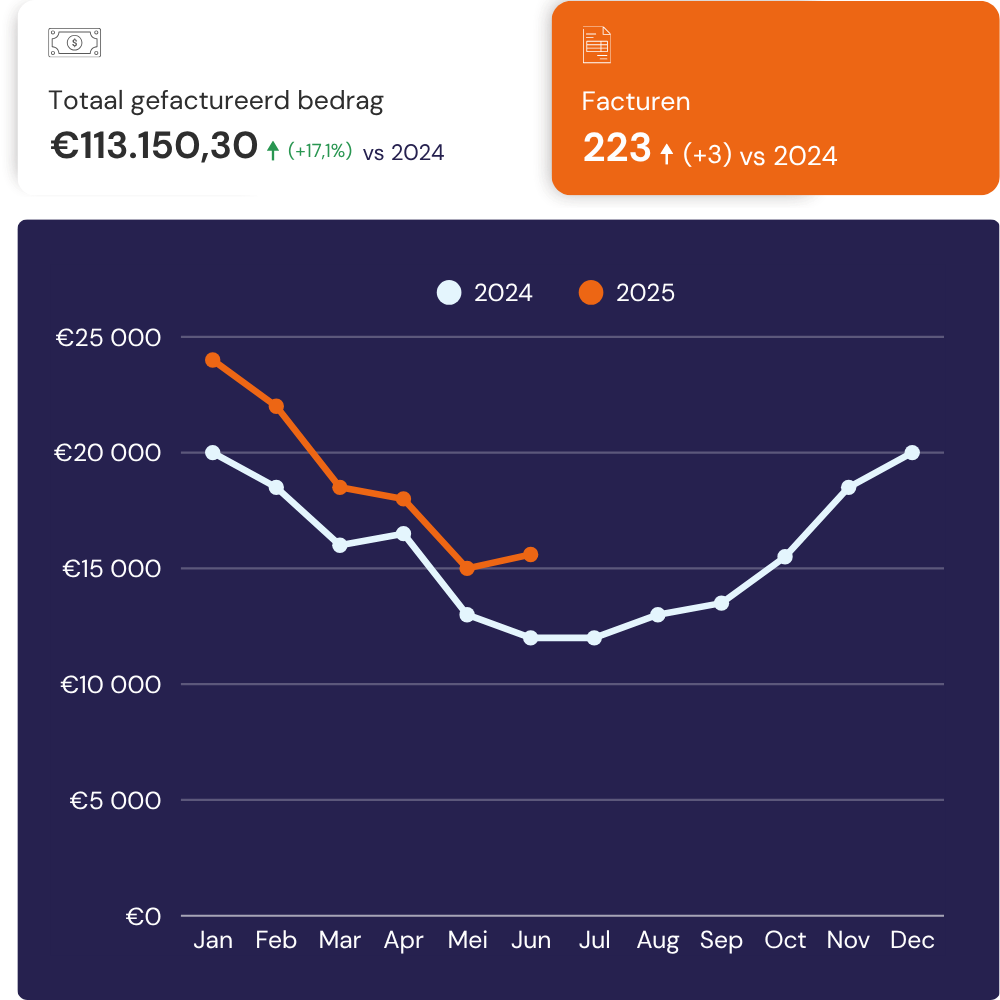
Volledig aangepaste Looker Studio-dashboards bovenop je Google-gegevensbronnen: GA4, Google Ads, Search Console, BigQuery, zodat je een live, nauwkeurig beeld krijgt van de prestaties.
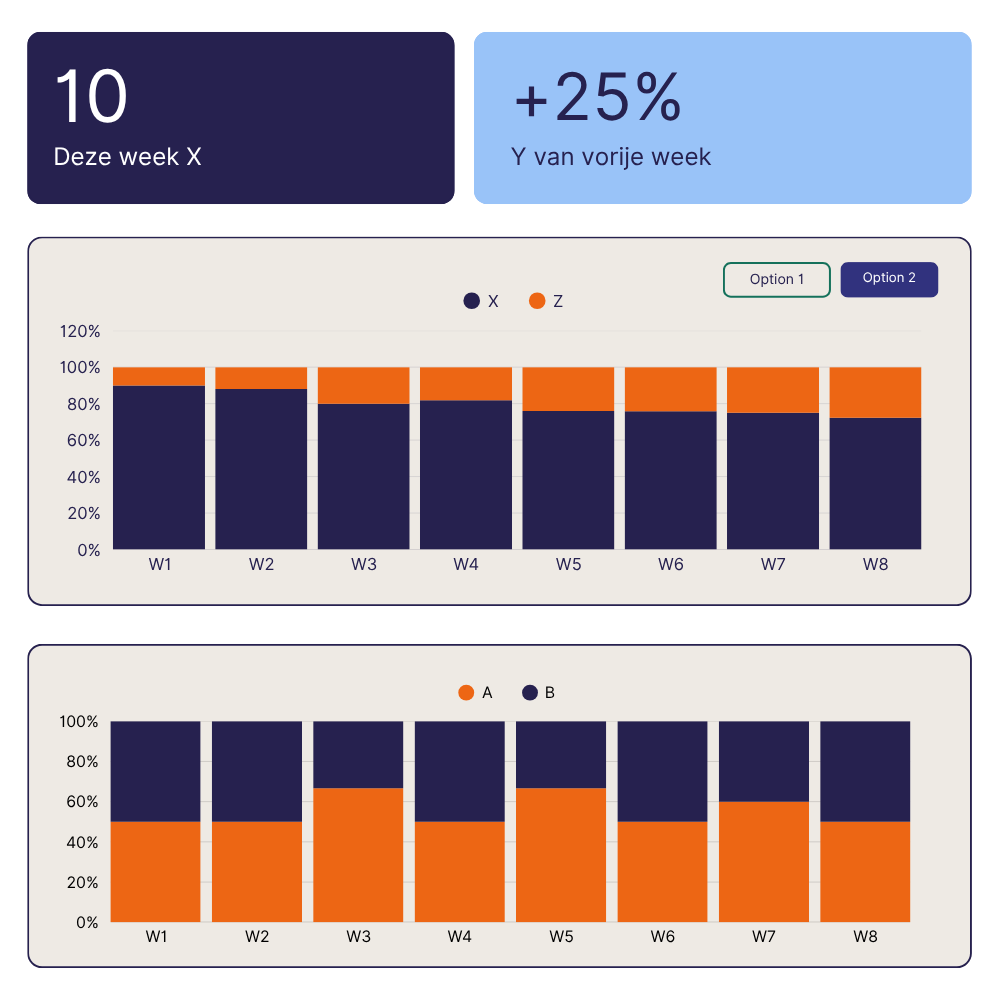
Als officiële Klipfolio-partner bouwen we aangepaste dashboards voor realtime KPI-monitoring over elke gegevensbron, sneller ingezet dan zwaardere BI-platforms en ondersteund door gecertificeerde partnerexpertise.
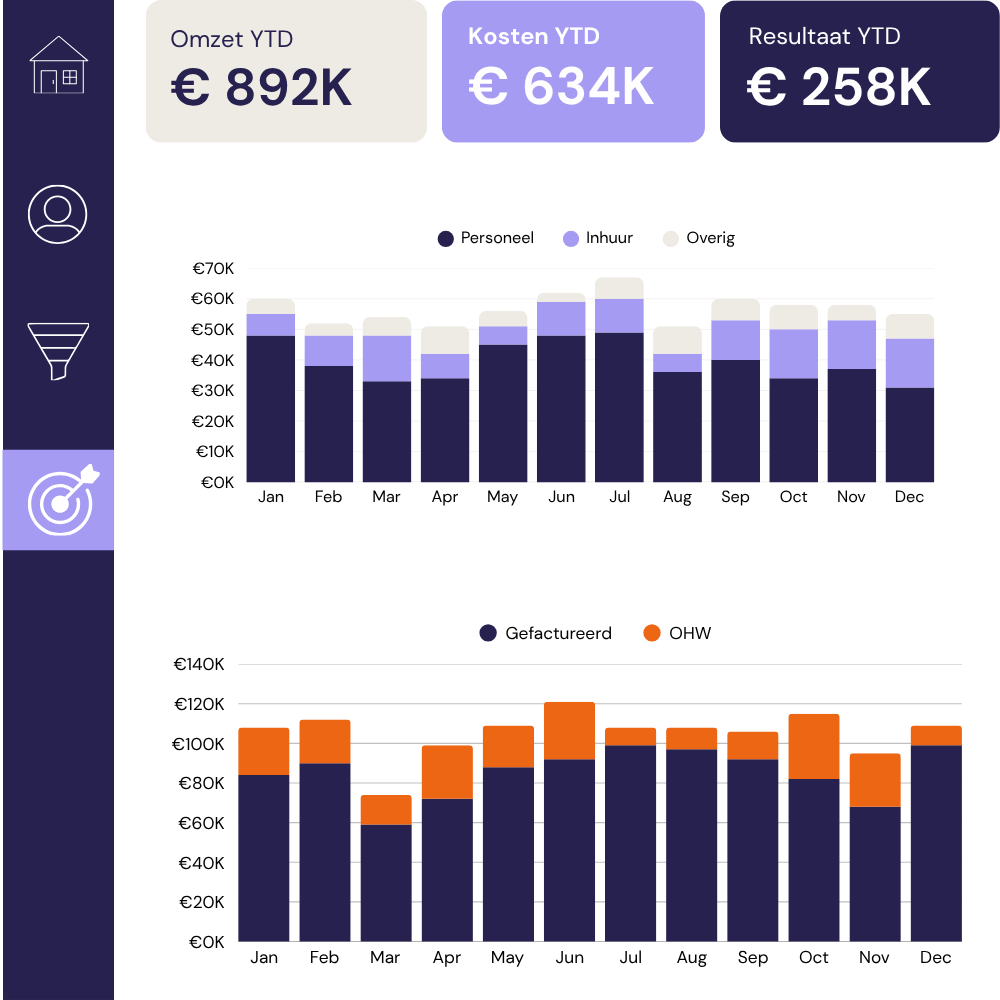
Als je bedrijf op Simplicate draait, maken we rechtstreeks verbinding met je omgeving en bouwen we een dashboard op maat dat je een live overzicht geeft van uren, projecten, pijplijn en marge.
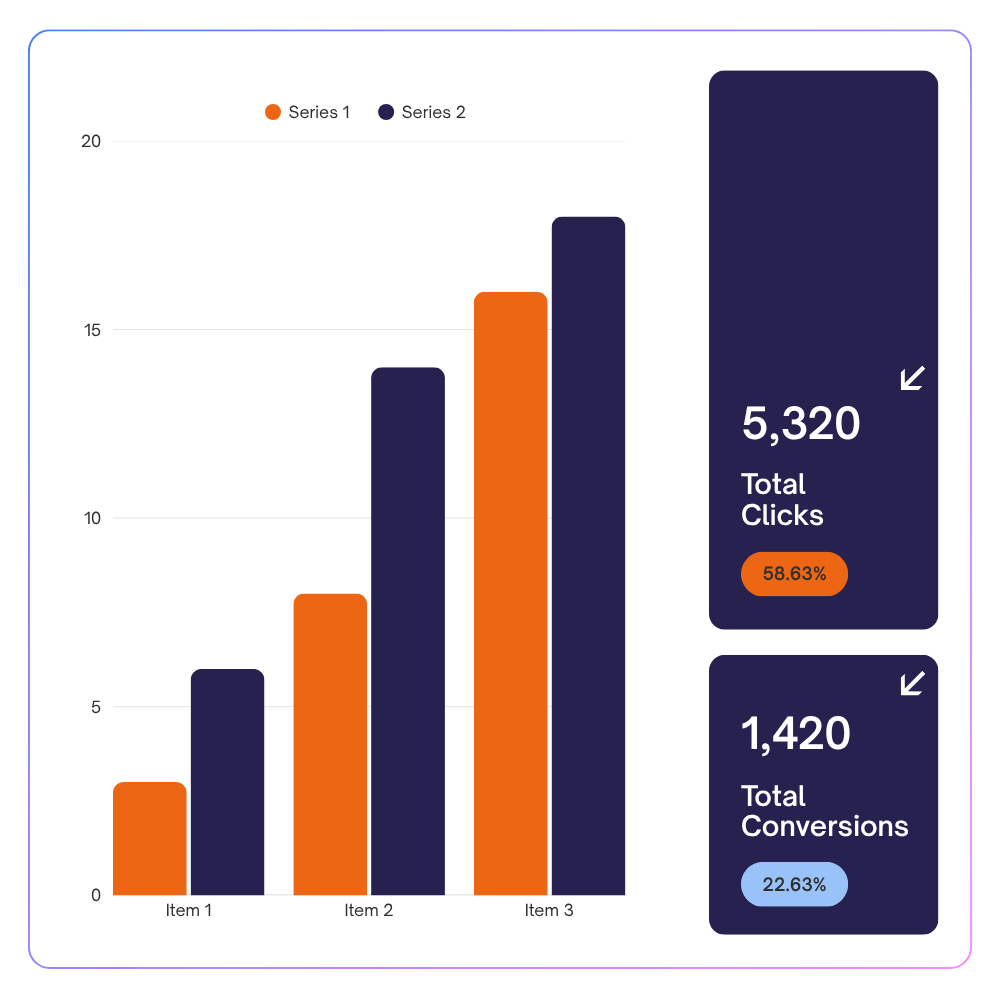
Voordat je investeert in datatools, -platforms of -aanwervingen, geeft een data-assessment je een eerlijk beeld van hoe je organisatie er op dit moment voor staat: wat werkt, waar zitten de gaten en een plan voor de volgende stap.
Sluit Claude Code rechtstreeks aan op je dbt en/of Power BI-omgeving in 1 dag, getest tegen je modellen en datasets; overhandigd met een walkthrough zodat je het meteen kunt gebruiken.
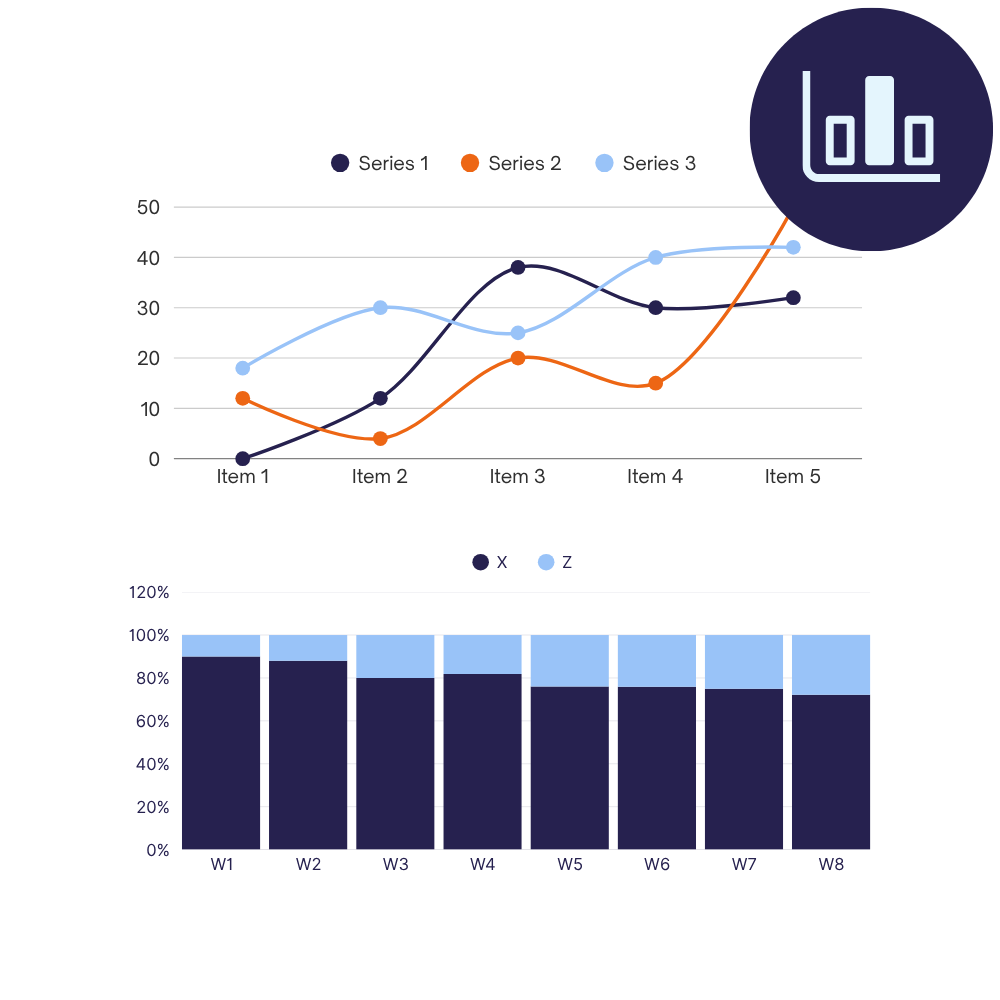
Voor B2B-bureaus en adviesbureaus die behoefte hebben aan praktisch inzicht in gegevens, bouwen we oplossingen op maat met live dashboards, gestructureerde gegevensuitvoer, geautomatiseerde KPI-waarschuwingen en interactieve rapporten.

Ben je op zoek naar iets dat je niet terugvindt in ons modulaire productaanbod? Onze data- en AI-expertise gaat veel verder dan wat hier wordt vermeld. Vertel ons wat je nodig hebt en wij bouwen het.