De data stack
3 maart 2019 | 5 minuten leestijd
Bij i-spark stellen wij commerciële bedrijven met online ambities, zoals webshops of abonnementsdiensten, in staat scherpere focus aan te brengen door nieuwe inzichten te verschaffen. Dat klinkt te gek, maar hoe doen wij dit dan?
Je kunt hier meer over lezen in onze blog over rentabiliteit en omzet.
Door bestaande data te analyseren, modelleren en visualiseren, door meetpunten die nu nog niet bestaan aan te brengen in websites of apps en door data uit alle hoeken en gaten bij elkaar te brengen. Maar dit allemaal lukt alleen wanneer je gebruik maakt van de juiste tools op het juiste moment en voor het juiste doel. Er is namelijk geen enkele tool die alle facetten van insights driven werken af kan dekken. Deze verzameling, of eigenlijk stapeling, van tools noemen wij de ‘data stack’ en kan voor onze klanten generiek of maatwerk zijn.
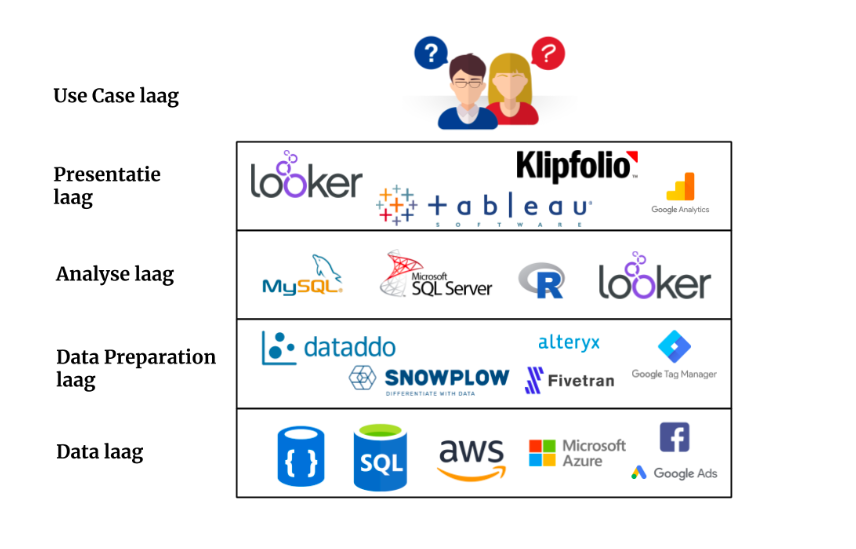
Het doel van data, big of small, is het oplossen van een business ‘probleem’. Laten we dit vanaf hier de use case noemen. Maar welke rol speelt de data stack in het oplossen van een use case? Hieronder leg ik de data stack uit, beginnend bij de onderkant van stack. Normaliter werk je ‘top down’ vanuit de use case, maar om de opbouw van de stack te begrijpen is het nu handiger om ‘bottom up’ te kijken.
Data laag
De onderste laag van de stack is de data zelf. Dit is de ruwe data die opgeslagen zit in allerlei bronnen zoals bijvoorbeeld SQL en NoSQL databases, datawarehouses en zelfs datalakes. Deze bronnen bevinden zich veelal in de cloud (Amazon AWS/Microsoft Azure/Google Cloud) of natuurlijk bij de klant zelf. De data uit deze bronnen kunnen worden ontsloten door directe koppelingen op bijvoorbeeld databases, maar ook via bijvoorbeeld API’s. In het geval van online marketing kun je de data uit je e-mailpakket, CRM, Google Analytics en Facebook (Ads) beschouwen als bron op dit niveau van de stack.Data Preparation laag
De volgende laag in de stack is de Data Preparation. Het klinkt misschien raar, maar data is over het algemeen rommelig en nooit in het juiste format wanneer je deze uit diverse bronnen probeert te combineren. Data Preparation is het proces van ophalen van de data uit bronnen, deze opschonen, samenvoegen en daarmee voor te bereiden voor analyse. Enkele bekende data preparation tools zijn Snowplow, Dataddo, Fivetran, Alteryx en Tableau Prep. Voor het ophalen van data uit bijvoorbeeld e-commerce websites maken we veelal gebruik van Google Tag Manager.Analyse laag
Nadat de data geschikt gemaakt is voor analyse, kunnen wij met behulp van SQL, R of SAS de vragen of use cases gaan beantwoorden. Sommige BI of visualisatie tools, zoals Looker, hebben een eigen ontwikkelde analyseprogrammeertaal die onze data consultants in staat stellen stelt om de analyse direct in de visualisatie tool te maken. Dit is ook de laag waar Machine Learning in allerlei vormen thuishoort. De uitkomsten kunnen direct gedeeld worden of worden gebruikt in de volgende laag van de stack. Overigens is deze laag niet altijd van toepassing op elke use case.Presentatie laag
De uitkomsten van de analyse laag kunnen dienen als input voor de presentatie laag. Het is ook mogelijk dat de input in deze laag direct vanuit de data preparation laag of zelfs data laag komt als er bijvoorbeeld sprake is van 1 bron. Een voorbeeld hiervan is Google Analytics. De data staat op een server bij Google en als eindgebruiker zie je deze verzamelde data in de interface van Google Analytics. De output van de presentatie laag hangt af van de use case en geldt vaak als ‘the last mile’ in data analyse:- In veel use cases is deze laatste stap een BI of visualisatie tool zoals Klipfolio, Looker of Tableau. Met behulp van deze tools worden de resultaten van een analyse of informatie uit een of meerdere bronnen visueel gemaakt zodat deze actionable inzichten creëren.
- In andere use cases kan het zijn dat de output van deze laag als feed voor andere systemen dient. Bijvoorbeeld enhanced ecommerce data uit je webshop dat via Google Tag Manager naar Google Analytics gestuurd wordt voor visualisatie van de verkopen. Maar ook productfeeds naar platformen zoals bijvoorbeeld Google Shopping, bol.com of Amazon.
Continue reading below
Contact Us
Ready to utilize your data?
Get in touch with our experts for a free consultation and see how we can help you unlock the full potential of your data.
Use Case Layer
De use case layer is de toplaag en het einddoel van de data stack. De use case bepaalt de keuze van tools in alle onderliggende lagen van de data stack. Het aantal use cases is bijna oneindig. Steeds veeleisendere use cases vragen om uitbreiding van data en creëren daarmee ook een groei in oplossingen in de data stack om inzichten te kunnen blijven genereren. Voorbeelden van Data Stacks
De gelaagdheid van een Data Stack is niet altijd zo plat zoals hierboven beschreven. Afhankelijk van de use case van de klant zijn er vele varianten op de stack te bedenken. Hieronder een tweetal voorbeelden van variatie in de gelaagdheid van de Data Stack
Voorbeeld 1:
Er is de wens om data uit een projectmanagement tool te visualiseren omdat de tool zelf daar niet voldoende in voorziet. De data is alleen te ontsluiten via een API met een limiet op 100 rijen data per request. Dit wil zeggen dat je maximaal 100 rijen aan data per keer kunt opvragen. Stel dat de bron 100.000 rijen bevat en dat de visualisatie tool, in dit geval Klipfolio, slechts 1 API request per keer aan kan. Dan moet je om alle data op te halen ruim 1000 datasources aanmaken. Dat is niet onderhoudbaar, onoverzichtelijk en zeer foutgevoelig. Om dit op te lossen is er een tussenstap nodig, namelijk het samenvoegen van de data uit alle benodigde API requests in Dataddo en vervolgens die data in een Google BigQuery database zetten. Zo brengen we het aantal benodigde datasources in Klipfolio terug naar slechts 1(!) en kunnen we naast visualisaties ook analyses doen op alle gecombineerde data. In deze use case bestaat de Data Stack uit een extra data laag:
Voorbeelden van Data Stacks
De gelaagdheid van een Data Stack is niet altijd zo plat zoals hierboven beschreven. Afhankelijk van de use case van de klant zijn er vele varianten op de stack te bedenken. Hieronder een tweetal voorbeelden van variatie in de gelaagdheid van de Data Stack
Voorbeeld 1:
Er is de wens om data uit een projectmanagement tool te visualiseren omdat de tool zelf daar niet voldoende in voorziet. De data is alleen te ontsluiten via een API met een limiet op 100 rijen data per request. Dit wil zeggen dat je maximaal 100 rijen aan data per keer kunt opvragen. Stel dat de bron 100.000 rijen bevat en dat de visualisatie tool, in dit geval Klipfolio, slechts 1 API request per keer aan kan. Dan moet je om alle data op te halen ruim 1000 datasources aanmaken. Dat is niet onderhoudbaar, onoverzichtelijk en zeer foutgevoelig. Om dit op te lossen is er een tussenstap nodig, namelijk het samenvoegen van de data uit alle benodigde API requests in Dataddo en vervolgens die data in een Google BigQuery database zetten. Zo brengen we het aantal benodigde datasources in Klipfolio terug naar slechts 1(!) en kunnen we naast visualisaties ook analyses doen op alle gecombineerde data. In deze use case bestaat de Data Stack uit een extra data laag:
 Voorbeeld 2:
De kosten uit campagnes van Google Ads staan in Google Analytics. Daarnaast bevat Google Analytics, via een Enhanced Ecommerce implementatie in Google Tag Manager, ook informatie over de verkopen van producten. Daarnaast wordt er ook via Facebook en Bing Ads geadverteerd. De informatie van campagnekosten uit beide bronnen worden gecombineerd met de informatie over verkopen in Klipfolio en gevisualiseerd als Cost Per Order per kanaal.
Voorbeeld 2:
De kosten uit campagnes van Google Ads staan in Google Analytics. Daarnaast bevat Google Analytics, via een Enhanced Ecommerce implementatie in Google Tag Manager, ook informatie over de verkopen van producten. Daarnaast wordt er ook via Facebook en Bing Ads geadverteerd. De informatie van campagnekosten uit beide bronnen worden gecombineerd met de informatie over verkopen in Klipfolio en gevisualiseerd als Cost Per Order per kanaal.
 Over het algemeen zijn er een aantal bekende combinaties van tools als Data Stacks te definiëren. Daarnaast hebben wij als experts ook een voorkeur voor een aantal tools die gezamenlijk als stack worden ingezet voor onze klanten, zeker wanneer het vergelijkbare use cases betreffen. Ter illustratie van een use case die wij vaker krijgen vanuit klanten is de geschetste Data Stack van voorbeeld 2 hierboven.
Enkele bekende data stacks zijn:
Over het algemeen zijn er een aantal bekende combinaties van tools als Data Stacks te definiëren. Daarnaast hebben wij als experts ook een voorkeur voor een aantal tools die gezamenlijk als stack worden ingezet voor onze klanten, zeker wanneer het vergelijkbare use cases betreffen. Ter illustratie van een use case die wij vaker krijgen vanuit klanten is de geschetste Data Stack van voorbeeld 2 hierboven.
Enkele bekende data stacks zijn:
- Snowflake - Fivetran - Looker
- AWS - Alteryx - Tableau
- Snowplow - SQL - Visualisatie tool
- API’s - Dataddo - Klipfolio
- Snowplow - Looker
- Google Tag Manager - Google Analytics
Data Engineer bij i-spark
Als Data Engineer speel ik een belangrijke rol in de advisering en inrichting van de juiste tools in elke laag van de Data Stack om de use cases van onze klanten te kunnen beantwoorden. De use cases en databronnen bij onze klanten zijn in 90% van de projecten duidelijk en aanwezig. Met behulp van mijn ervaring in development en product management kan ik vervolgens samen met het i-spark team en de klant zoeken naar hoe we de Data Stack kunnen inzetten bij verschillende use cases. En zo brengen wij data uit alle hoeken en gaten bij elkaar én kun jij als commercieel bedrijf met online ambities scherpere focus verkrijgen door nieuwe inzichten. Nieuwsgierig naar wat wij voor jouw use cases kunnen betekenen? Mail of bel ons! neem contact op JeroenWant to activate your data too?
We provide custom solutions tailored to your organization at a great price. No huge projects with months of lead time, we deliver in weeks.