Nearly everyone who frequently handles large data sets is aware of the common issue of databases lacking a clear organizational structure. Data pulled from multiple sources often gets stored in varied schemas within the data warehouse, letting analysts work on tables scattered across the entire database. Without a clear consensus on database structure, organizing your data and enhancing its quality can become quite problematic.
What is the ‘Medallion Architecture’?
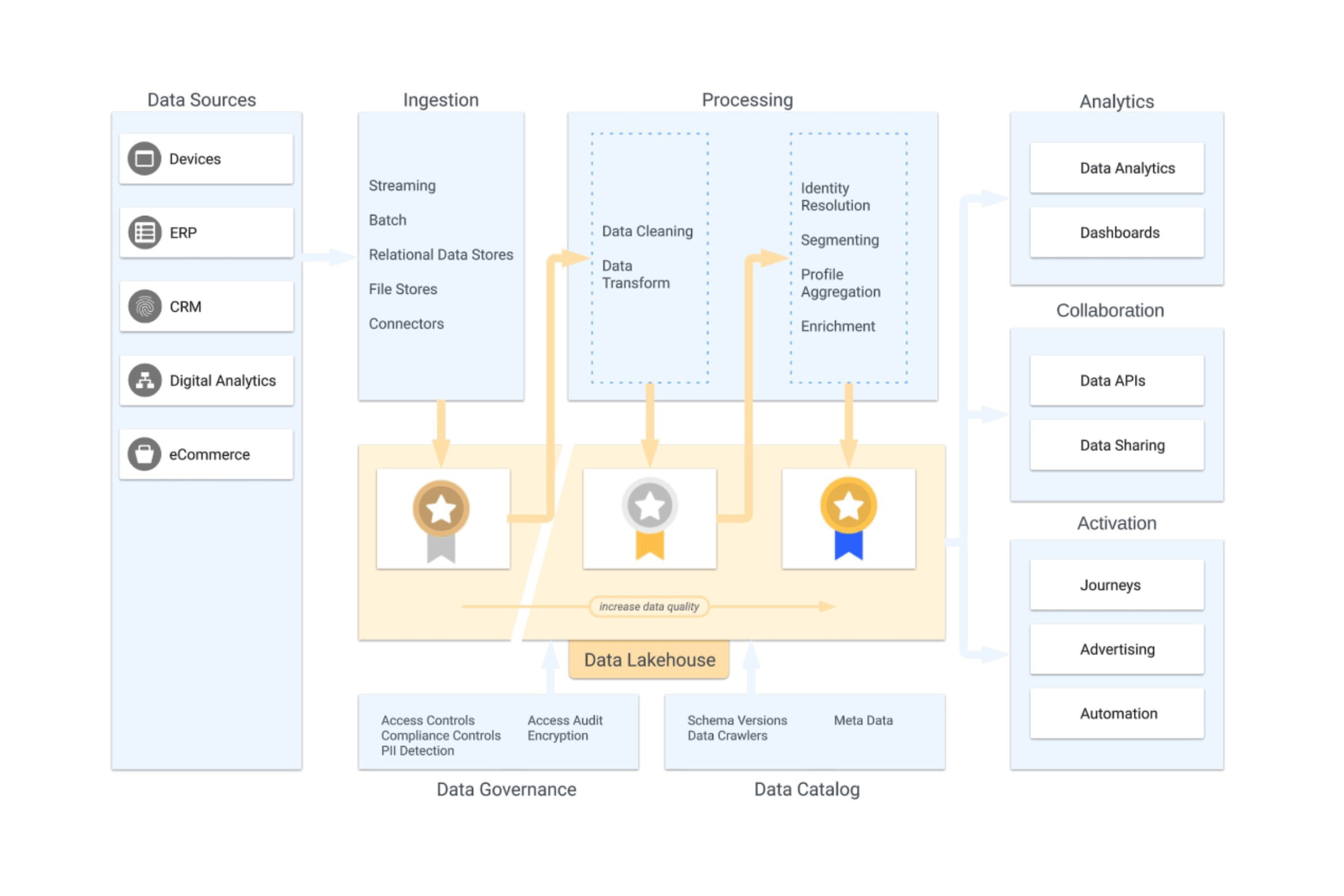
To enhance data quality across various stages and establish a clear structure within your data lakehouse, Databricks introduced the ‘Medallion Architecture’ a few years back.This architecture, based on the three different medal gradations, forms a clear framework for enhancing data quality by restructuring and transforming data in three different layers or phases, namely: bronze, silver, & gold.
Bronze
The bronze layer consists of data that is stored ‘as-is’ in the data warehouse. This data is usually collected incrementally from various sources, often with the help of APIs and SaaS tools like Fivetran or Dataddo, and stored in raw form. That is to say, in this phase, little to no transformations are applied to the data. In this way, a significant history of data is built up as files in your cloud platform or as tables in your data warehouse.
Silver
In the silver layer, the data from the bronze layer is then transformed. In this phase, data is made more insightful by deduplicating, combining sources, filtering, standardizing, etc. A significant step is made in improving the quality of the data in this phase. These transformation processes are often built with SQL models in dbt. Dbt is a popular tool in the data world for efficiently and effectively transforming big data.
Gold
In the gold layer of the data warehouse, we then store data that has been further transformed and aggregated so that it is fully ready for valuable reports in BI tools and as input for Data Activation tools or Machine Learning models. This data is optimized so that its retrieval can be efficiently carried out by tools that are linked to this schema of the data warehouse.
How does this architecture differ from others?
By deduplicating, aggregating, and transforming data in different steps, only the data that is prepared for analysis ends up in the gold layer of your data lakehouse. These optimized tables ensure that running dashboards and reports in BI tools is efficient. This is due to the minimal need for complex aggregations or additional transformations within the BI tools themselves. This greatly reduces the time required to run your dashboards.
The Medallion Architecture sets itself apart by managing permissions for specific tables and schemas within your data lakehouse. By segregating raw, validated, and enriched data across distinct areas of your database, you can allocate and restrict certain rights for particular user groups within an organization. Typically, you might grant data engineers full access to tables in the bronze layer, while limiting their rights in the gold layer. Conversely, analysts might be given broader permissions for the tables in the gold layer.
What are the pros and cons of the ‘Medallion Architecture’?
We choose to work with this framework for a variety of reasons and often recommend its implementation to our clients. The primary reasons include:
- Simplicity. This architecture for a data model is easy to understand across the entire organization. This makes working with this architecture uncomplicated. This architecture is also well-suited for larger organizations such as holdings. Data from different companies under an overarching organization can easily be separated into these layers in your database. By reporting on information from the gold layer, multiple truths for certain measurements do not arise. This is an issue often encountered when a clear structure is lacking in the data warehouse.
- Data Integrity. With this architecture, you always retain the raw form of your data. This makes it easy to completely rebuild incremental tables, easily correct errors, and simply add new columns to tables further along in your transformation processes. This makes it easy to create new aggregations on one hand, and on the other hand, provides additional security because the architecture is fault-tolerant. You retain your data as it has been extracted from the sources.
- Flexibility and modularity. Because a wide variety of aggregations between different sources is possible, analysts can get creative to achieve valuable insights. And all this without having to manipulate other models, which could cause interference in other processes due to interdependencies.
Certainly, while there are many benefits to the Medallion Architecture, it’s not without its challenges. From our perspective, one notable drawback is as follows:
- This architecture might result in greater storage needs compared to other frameworks. If your data platform taps into various sources with data that demands minimal or no transformations, this architecture may not be the best fit. You’d find yourself storing data that remains largely unchanged across the various layers of your data lakehouse. Consequently, this increased storage requirement could translate to higher costs.
Conclusion
The Medallion Architecture provides a framework for establishing a clear structure in your data warehouse. With this structure, we differentiate between raw, validated, and enriched data by storing these different levels of data quality in separate layers of the data warehouse, namely the bronze, silver, and gold layers. The quality of the data is enhanced at each layer through validations, transformations, and aggregations. This approach creates a single version of the truth in the gold layer, optimized for efficient analysis and reporting in BI tools. Additionally, the Medallion Architecture always preserves the data in its raw form, offering an extra layer of security against the loss of valuable information. It also allows for flexibility and creativity in handling new aggregations with data from recently added sources. Due to its clear structure and flexibility, we see significant benefits in working with the Medallion Architecture and therefore prefer to implement it in data lakehouses and warehouses.
Ready for action?
Are you not yet using the Medallion Architecture to increase your data quality, but have we made you curious? We are happy to advise you on how you can integrate this into your data management. If you want, we can even take a large part of this process off your hands. Please feel free to contact us for the possibilities.


